Continues the series of post related to analyzing catalogue data, here are some stats on author “significance” as measured by the number of book entries (‘items’) for that author in the Cambridge University Library catalogue from 1400-1960 (there being 1m+ such entries).
I’ve termed this measure “significance” (with intentional quotes) as it co-mingles a variety of factors:
- Prolificness – how many distinct works an author produced (since usually each work will get an item)
- Popularity – this influences how many times the same work gets reissued as a new ‘item’ and the library decision to keep the item
- Merit – as for popularity
The following table shows the top 50 authors by “significance”. Some of the authors aren’t real people but entities such as “Great Britain. Parliament” and for our purposes can be ignored. What’s most striking to me is how closely the listing correlates with the standard literary canon. Other features of note:
- Shakespeare is number 1 (2)
- Classics (latin/greek) authors are well-represented with Cicero at number 2 (4), Horace at 5 (9) followed Homer, Euripides, Ovid, Plato, Aeschylus, Xenophon, Sophocles, Aristophanes and Euclid.
- Surprise entries (from a contemporary perspective): Hannah More, Oliver Goldsmith, Gilbert Burnet (perhaps accounted by his prolificity).
- Also surprising is limited entries from 19th century UK with only Scott (26), Dickens (28) and Byron (41)
| Rank | No. of Items | Name |
|---|---|---|
| 1 | 3112 | Great Britain. Parliament. |
| 2 | 1154 | Shakespeare, William |
| 3 | 1076 | Church of England. |
| 4 | 973 | Cicero, Marcus Tullius |
| 5 | 825 | Great Britain. |
| 6 | 766 | Catholic Church. |
| 7 | 721 | Erasmus, Desiderius |
| 8 | 654 | Defoe, Daniel |
| 9 | 620 | Horace |
| 10 | 599 | Aristotle |
| 11 | 547 | Voltaire |
| 12 | 539 | Virgil |
| 13 | 527 | Swift, Jonathan |
| 14 | 520 | Goethe, Johann Wolfgang Von |
| 15 | 486 | Rousseau, Jean-Jacques |
| 16 | 479 | Homer |
| 17 | 444 | Milton, John |
| 18 | 388 | Sterne, Laurence |
| 19 | 387 | England and Wales. Sovereign (1660-1685 : Charles II) |
| 20 | 386 | Euripides |
| 21 | 372 | Ovid |
| 22 | 358 | Goldsmith, Oliver |
| 23 | 358 | Plato |
| 24 | 351 | Wang |
| 25 | 349 | Alighieri, Dante |
| 26 | 338 | Scott, Walter (Sir) |
| 27 | 326 | More, Hannah |
| 28 | 322 | Dickens, Charles |
| 29 | 315 | Aeschylus |
| 30 | 304 | Burnet, Gilbert |
| 31 | 302 | Luther, Martin |
| 32 | 295 | Dryden, John |
| 33 | 290 | Xenophon |
| 34 | 280 | Sophocles |
| 35 | 262 | Pope, Alexander |
| 36 | 259 | Fielding, Henry |
| 37 | 258 | Li |
| 38 | 250 | Calvin, Jean |
| 39 | 248 | Zhang |
| 40 | 247 | Aristophanes |
| 41 | 247 | Byron, George Gordon Byron (Baron) |
| 42 | 247 | Bacon, Francis |
| 43 | 24have 7 | Chen |
| 44 | 245 | Terence |
| 45 | 241 | Euclid |
| 46 | 235 | Augustine (Saint, Bishop of Hippo.) |
| 47 | 232 | Burke, Edmund |
| 48 | 223 | Johnson, Samuel |
| 49 | 222 | Bunyan, John |
| 50 | 222 | De la Mare, Walter |
Top 50 authors based on CUL Catalogue 1400-1960
The other thing we could look at is the overall distribution of titles per author (and how it varies with rank – a classic “is it a power law” question). Below are the histogram (NB log scale for counts) together with a plot of rank against count (which equates, v. crudely, to a transposed plot of the tail of the histogram …). In both cases it looks (!) like a power-law is a reasonable fit given the (approximate) linearity but this should be backed up with a proper K-S test.
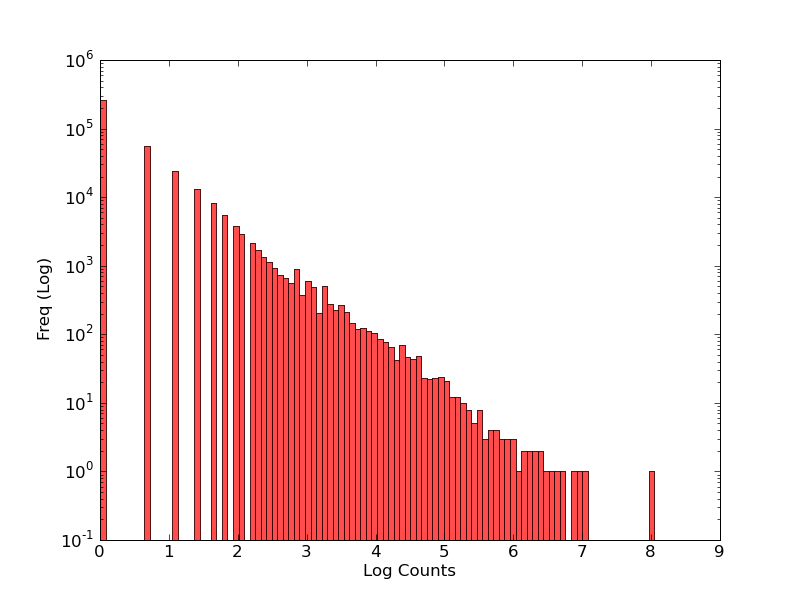
Histogram of items-per-author distribution (log-log)
![]()
Rank versus no. of items (log-log)
TODO
- K-S tests
- Extend data to present day
- Check against other catalogue data
- Look at occurrence of people in title names
- Look at when items appear over time
Colophon
Code to generate table and graphs in the open Public Domain Works repository, specifically method ‘person_work_and_item_counts’ in this file: http://knowledgeforge.net/pdw/hg/file/tip/contrib/stats.py